
Blog
18
kwi 2022
Szybki bas.
W określeniach potocznych na sekcję niskotonową bardzo często pojawia się określenie dotyczące brzmienia „szybki bas”. Jest ono oczywiście znacznie mniej precyzyjne niż opisanie zjawiska wykresami, ale jako takie pomaga za pomocą mowy potocznej przy ocenie właściwości tego co ucho słyszy a ciało odbiera poprzez drgania. Skąd się wzięło i czy bas może być szybki albo wolny?
Ten mit można uznać za częściowo potwierdzony. Jednakże trzeba na wstępie powiedzieć przede wszystkim, że określenie „szybki” jest użyte nieprawidłowo a ocena „szybkości” w istocie nie dotyczy narzędzia jakim jest subwoofer, a dźwięku instrumentu i/lub jego realizacji czyli tego co powstaje w efekcie zamysłu twórcy muzyki na etapie tworzenia. Bas jako składowa pasma, a nie jako narzędzie, nie może być szybszy lub wolniejszy. To jest dokładnie taki sam błąd myślowy jak długi i krótki słupek w piłce nożnej. Wszak prędkości dźwięku jest w ośrodku stała, oczywiście dźwięki docierają tak samo szybko niezależnie od częstotliwości (340m/s). Gdyby było inaczej dźwięk by się drastycznie zmieniał w zależności od odległości od źródła dźwięku. Szybki bas przecież czym dalej od zróła, to docierasłby szybciej czyli wcześniej niż pozostałe pasmo, albo bas wolny. Chodzi o zatem o coś zupełnie innego niż szybkość. Per analogia w piłce nożnej prawidłowym określeniem jest słupek bliższy i słupek dalszy. Prawidłowe określenie tego co słyszymy powinno brzmieć bas „wcześniejszy” albo „późniejszy”. Gdy przyjrzymy się typowemu wykresowi ciśnienia, jakie powstaje w wyniku uderzenia w strunę albo membranę instrumentu, odnajdziemy w nim pewną powtarzalną cechę. Na przykładzie tego utworu widzimy falę akustyczną, z zaznczoną sekcją samego uderzenia tempa o czasie około 0,35s. Sygnał został odfiltrowany powyżej 70Hz i poniżej. Widzimy, że każde pasmo występuje w innym miejscu w czasie.
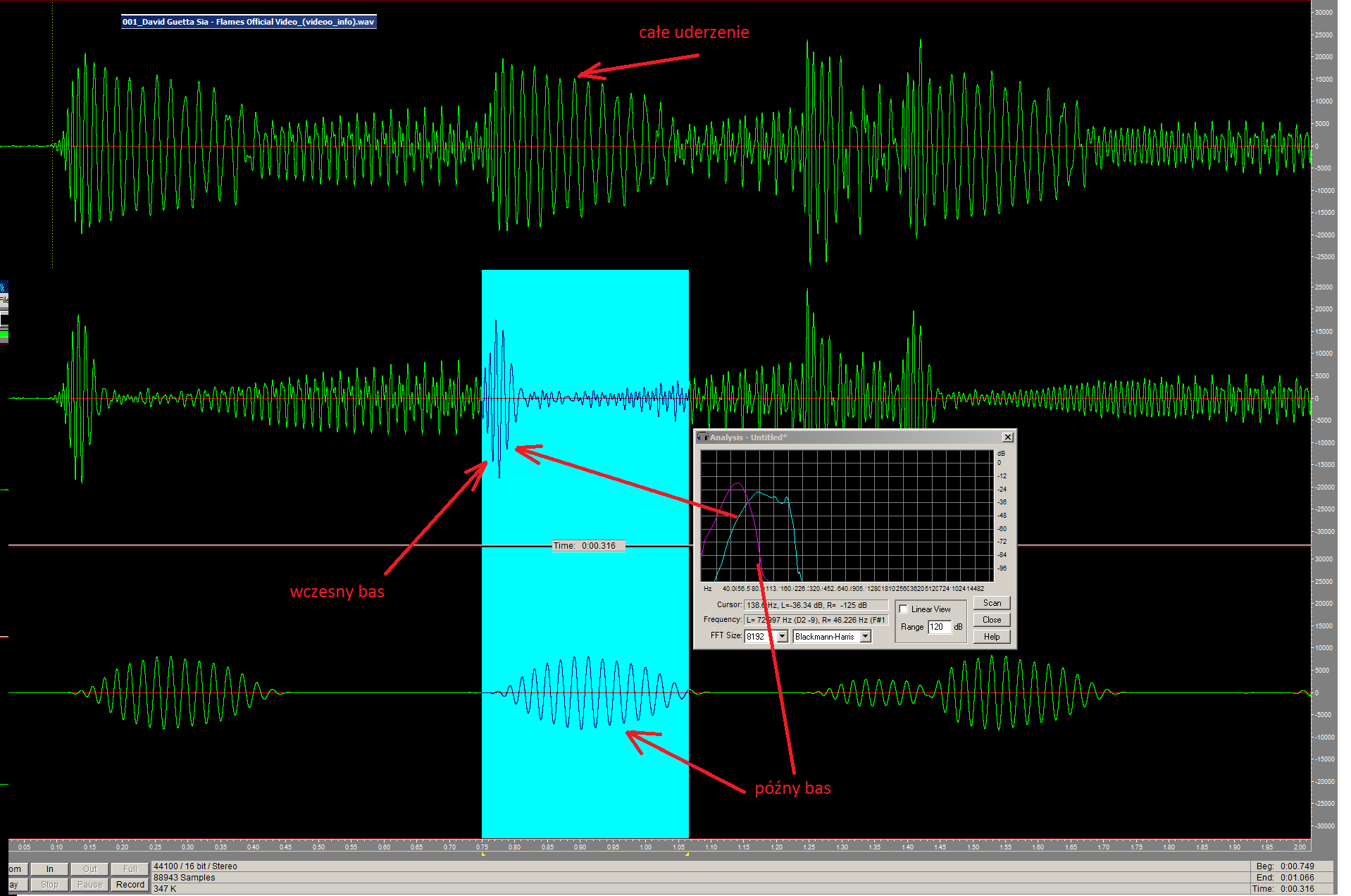
W pierwszej kolejności pojawiają się tony najwyższe i trwa to krótko, a następnie wraz z czasem wybrzmiewania, częstotliwość się obniża i sygnał mniej lub bardziej wydłuża w czasie. Nigdy odwrotnie. Dawniej obserwacja wykresów w funkcji czasu wymagała użycia narzędzi lub programów specjalistycznych, ale wraz z popularyzacją cyfrowych mikserów zawierających analizator widma, to samo można zaobserwować na wykresie amplitudy w funkcji częstotliwości. Nie tylko częstotliwości, ale i moce (poziomy) sygnałów występujące w zależności czasu, czyli powiedzmy obwiednia sygnału jest cechą charakterystyczną linii perkusyjnej i bywa różnorodna: czasami początek jest najsilniejszy, następnie się obniża szybciej, a czasami wolniej, a czasami nawet powiększając swoją moc. Tym nie mniej kolejność jest zawsze taka sama: wpierw pojawiają się częstotliwości wyższe. Sytuacja odwrócenia kolejności jest w zasadzie niespotykana, a dla słuchu brzmi jak coś obcego lub muzyka puszczona od tyłu. Nawet w utworach wykorzystujących sample puszczone od tyłu, wspomnę chociażby (Outkast „ms Jackson” ) linia perkusyjna jest nagrana klasycznie. Skoro zatem miejsce (kolejność) w czasie danego pasma jest określone, to odpowiednie zwiększenie nacisku na inne pasmo np za pomocą korektora EQ, może dawać wrażenie że tenże instrument wybrzmiewa nutę wcześniej lub później.
Mając tę podstawę, nietrudno będzie mi wyjaśnić, że w przypadku odbioru wrażenia słuchowego, wczesność uderzenia (bitu) zależy, przede wszystkim od samego instrumentu, ale pomijając oczywiście celowy lub nieudolny efekt pracy realizatora, także od krzywej amplitudowej systemu nagłośnieniowego. Wszak uwypuklenie wysokich basów daje odczucie że bas występuje wcześniej, lub po prostu jest na swoim miejscu. Brak wysokich basów (80-200Hz) powoduje odczucie, że bas jest wręcz opóźniony względem linii melodycznej. Bark basów niskich (<50Hz), oprócz braku ogólnie lubianej głębi, powoduje z kolei skrócenie wybrzmiewania, co powoduje degradację wierności. Może to być jednak w trudnych warunkach akustycznych (zbyt długi czas pogłosu, fala stojąca) korzystnym zabiegiem nie tyle artystycznym, co praktycznym: po prostu ułatwia trzymanie tempa, trafianie w strunę w moment. Długość wybrzmiewania i szybkość uderzenia nie powinna jednak zależeć od narzędzia, tylko od artysty, czy realizatora. Realizator może i powinien ingerować wg własnego pomysłu w torze wejściowym kluczowych instrumentów, by uzyskać zamierzony efekt. Ale zachowując niezależność od różnych źródeł emitowanych przez system, nie powinien tego robić w torze wyjściowym zbiorczym dla wszystkich ścieżek, a tym bardziej bezsensowym jest robienie tego podczas zakupu narzędzia jakim jest subwoofer.
System nagłośnieniowy, który zapewnia wyrównaną (nie płaską) krzywą amplitudowo fazową pozwala na wytworzenie zarówno to co basy szybkie (wczesne) jak i długie (późne) i z punktu widzenia jakości jest to rozwiązanie najlepsze, bo pozwala osobie która używa narzędzia, czy to np artyście, czy to realizatorowi na uzyskanie dowolnego efektu. Z kolei system który sam w sobie deformuje dźwięk, eksponuje bardziej tylko dźwięki szybkie lub tylko wolne uniemożliwia realizację pomysłu, czy też nie odzwierciedla wcześniej przygotowanego brzmienia.
Często zaboboniarze popierający teorię „szybkiego subwoofera” używają argumentu „bezwładności membrany”, tłumacząc sobie na chłopski rozum istotę zjawiska. Powszechnie uważa się, że duża membrana, np 18calowa jest bardziej bezwładna, niż mniejsze i to powoduje, że jest wolniejsza. To dość popularny mit, który nie ma nic wspólnego z rzeczywistością. Generalnie prawie całe pasmo użyteczne , czyli pasmo równomiernego przetwarzania prawie każdego głośnika jest w zakresie bezwładnościowym membrany, bez względu na rozmiar – nawet w driverach wysokotonowych. Bezwładność membrany powoduje, że wychylenie membrany spada proporcjonalnie do częstotliwości, a w efekcie wzrostu efektywności przetwarzania tłoka na dźwięk, SPL utrzymuje się na stałym poziomie w paśmie, mówiąc chyba prościej, dzięki temu zjawisku krzywa amplitudy jest płaska w częstotliwości. Masa membrany decyduje w typowym ustroju, nie o górnej częstotliwości granicznej, a przede wszystkim o skuteczności, a pasmo niemalże każdej 18stki przekracza kilkakrotnie okolice 100Hz, do których używane są zwykle subwoofery. Ponadto nawet najmocniejsze 18calowe głośniki promieniują bez problemu kilkakrotnie większe częstotliwości, niż górna częstotliwość do której ogranicza się pasmo subwoofera za pomocą crossovera (zwykle w okolicy 100Hz).
W praktyce posiadając nawet najlepsze narzędzia, które mają wystarczająco pełne pasma, zepsuć efekt może nieprawidłowe zestrojenie crossovera oraz fizyczne ustawienie przetworników, w tym np. oddalenie subwoofera od mid-hi LR może powodować niedoskonałości w okolicach pasma podziału (zwykle ok 100Hz) które mogą być odbierane jako mające wpływ na szybkość basu. Największym jednak problemem jest moim zdaniem trudność w uzyskaniu odpowiedniej skuteczności nadstawki w pasmie dla niej najniższym, czyli 100-300Hz. Jest to szczególnie istotny problem z uwagi, że bas jest głośniejszy, więc przejście między bas/ sat w pasmie powinno być płynne. To oznacza, że chcemy w tym pasmie od nadstawki najwięcej w jej pasmie, a przecież nadstawka pracuje w pełnej przestrzeni co powoduje że właśnie w tym paśmie jest jej najtrudniej.
Reasumując. Idealnym narzędziem jest sub, który odtwarza zarówno wczesny jak i póżny bas, a reszta systemu nadąża z nim, wszak pasmo mikrofonów używanych do stopy sięga przeciez 10kHz.
28
paź 2015
Prawo podwajania głośnika
Wzajemna impedancja promieniowania.
Jedną z dość dziwnych zasad panujących w akustyce jest ta, że przy zestawieniu ze sobą dwóch źródeł szczególnie dla niskich częstotliwości, uzyskujemy więcej nie o 3dB, co wydawałoby się intuicyjne, ale więcej o 6dB. Dlaczego nie 3dB? Otóż dlatego, że dostawienie drugiego subwoofera (jak i dalsze podwojenie), zwiększa nie tylko łączną moc dostarczoną dwukrotnie (3dB) , ale jednocześnie efektywność każdego z nich wzrasta dwukrotnie, co daje kolejne 3dB zysku. Przykładowo licząc: subwoofer o efektywności 97dB i mocy1000W (+30dB) pozwoli uzyskać 127dB. Logiczne wydawałoby się, że dostawienie drugiego basu i zasilenie go taka samą mocą spowoduje dwukrotny wzrost natężenia, które jest przecież proporcjonalne do mocy dostarczonej do głośników. Myśląc w ten sposób otrzymalibyśmy 130dB. W rzeczywistości jest inaczej. Okazuje się, że dostawiając drugi subwoofer zwiększamy możliwości systemu do 133dB. Wynika to z tego, że efektywność dwóch subwooferów zwiększa się z 97dB do 100dB.
Z czego to wynika?
Do problemu można podejść z dwóch stron otrzymując ten sam wynik. Zacznę od podstaw.
Równania różniczkowe, które opisują zależności prądu i napięcia, są identyczne jak równania ciśnienia i prędkości powietrza w akustyce, oraz prędkości obiektu i jego masy drgającego w mechanice. Z tego powodu dla ułatwienia rozwiązania tych równań w elektroakustyce wprowadza się schematy zastępcze, które można liczyć tak samo jak te znane w elektrotechnice. Różnica jedynie taka, że masa membrany, czy masa współdrgającego ośrodka są odpowiednikiem indukcyjności cewki, a sprężystość zawieszenia, czy sprężystość powietrza w komorze są odpowiednikiem pojemności kondensatora. Odpowiednikiem zjawiska oporu w mechanice jest tarcie, a w elektroakustyce promieniowanie dźwięku poza układ. Różnica jest taka, że tarcie zamienia energię w ciepło, a promieniowanie zamienia energię na dźwięk. Przy okazji zwrócę uwagę, że dla impedancji promieniowania podobnie jak w elektrotechnice dla oporu siła reakcji ma zwrot przeciwny do prędkości (prądu). Można w ten sposób stworzyć schemat zastępczy głośnika (dla każdej obudowy o parametrach skupionych), który jest dość łatwo przyswajalny i prosty do obliczenia ze względu na dużą popularność elektrotechniki. W schemacie tym kluczowa część schematu to: źródło napięcia (siły) zasilające szeregowe połączenie impedancji elektrycznej cewki z impedancją promieniowania membrany. W schemacie tym w zależności od obudowy znajdują się różne inne elementy, ale są to głównie elementy bierne czy straty tarcia w głośniku które dla zrozumienia idei nie są kluczowe.
W takim prostym układzie szeregowym z dzielnikiem: Źródło +Z1+Z2, sprawność przetwarzania energii zależy od tego jak dużo energii czynnej wydzieli się na impedancji promieniowania membrany (w postaci dźwięku) w porównaniu do tej energii która wydzieli się w postaci ciepła na impedancji cewki. Oczywiście impedancje te są zmienne dla rożnych częstotliwości, ale dla ułatwienia zrozumienia tej ogólnej zasady: dopóki rezystancja (impedancja) promieniowania jest mała w porównaniu do rezystancji (impedancji) cewki, to skuteczność jest proporcjonalna do wartości tej rezystancji (impedancji) promieniowania.
Dlaczego impedancja promieniowania jest znacznie mniejsza niż impedancja cewki? Otóż powietrze jest na tyle rzadkim ośrodkiem, że dość duża prędkość membrany powoduje stosunkowo niskiej wartości siłę reakcji ośrodka na ten ruch. Dokładnie z tego powodu, sprawność przetwarzania głośników niskotonowych promieniujących bezpośrednio, jest dość niska, w najlepszym przypadku rzędu 1-2%.
Proszę zwrócić uwagę, że przy tej samej prędkości membrany, siła oporu powietrza jaka działa na membranę pierwszego głośnika będzie większa, jeśli drugi identyczny głośnik postawimy blisko na tyle, że przepompowywane przez niego powietrze będzie znacząco hamować membranę pierwszego. Skoro impedancja akustyczna jest mierzona stosunkiem siły do prędkości, to jasne staje się, że impedancja akustyczna pierwszej membrany rośnie.
Dla zobrazowania tego zjawiska polecam zrobić prosty test praktyczny: Proszę zaobserwować, że podłączony jeden głośnik, będzie poruszał membraną drugiego głośnika, który nie jest podłączony.
Wykorzystując zjawisko, że w odległości porównywalnej lub mniejszej od średnicy membrany ciśnienie jest prawie niezależne od odległości, to upraszając siła oddziałująca na membranę głośnika obok jest taka sama jak siła oddziałująca przez otoczenie na membranę drgającą samodzielnie. Uruchamiając więc drugą membranę, łącznie siła rośnie dwukrotnie, dając dwukrotny wzrost impedancji (można skorzystać ze znanej w elektrotechnice zasady superpozycji). Ponieważ zwiększona impedancja promieniowania, powstaje pod wpływem drugiego źródła na pierwsze, a dokładnie to samo dzieje się z wpływem pierwszej membrany na drugą, to ten wzrost nazywany jest impedancją wzajemną promieniowania (można ją dołączyć w szereg do schematu). To ona powoduje, że każdy z głośników ma dwukrotnie większą wypadkową impedancję promieniowania a przez to ma dwukrotnie większą sprawność.
Do problemu można tez podejść z drugiej strony. Jak już objaśniłem wcześniej, skuteczność jest proporcjonalna do impedancji promieniowania membrany. Impedancja promieniowania czyli stosunek siły do prędkości, dla częstotliwości odpowiednio dużej jest równa impedancji falowej ośrodka pomnożonej przez powierzchnię promieniującą, ponieważ ciśnienie, w tym także ciśnienie akustyczne zależy od iloczynu siły i powierzchni. Częstotliwość odpowiednio duża to taka, która powoduje, że cząsteczki powietrza nie mają czasu ociec z membrany poza jej obręb, przekazują ciśnienie kolejnym cząsteczkom tworząc falę. Dla rozwiania wątpliwości, w jakim zakresie pracują głośniki niskotonowe przypomnę, że dla 40Hz długość fali wynosi 8m, a membrana 18’’ ma około 40cm, więc nie ma wątpliwości, że przy tak niskiej częstotliwości większość powietrza z membrany ucieka w czasie krótszym niż półokres fali. Jest to dokładnie ten sam powód, dla jakiego sprawność głośników niskotonowych jest niska, o czym pisałem już powyżej. To trochę tak, jakbyśmy lali wodę do zbiornika poprzez rurkę wielokrotnie większą od zbiornika. W efekcie tylko część z cząsteczek przekazuje energię do ośrodka,a reszta się wylewa. Ta część jest proporcjonalna do stosunku powierzchni membrany do długości fali. W efekcie dla danej częstotliwości impedancja promieniowania (przeniesiona na stronę mechaniczną) zależy od kwadratu powierzchni membrany. Zależność od kwadratu powierzchni jest oczywiście również znana z doświadczeń. Z tego powodu staramy się robić głośniki niskotonowe jak największe: czym większy głośnik, tym bardziej sprawny (przy tym samym ciężarze membrany). Tutaj na wszelki wypadek, żeby rozwiać wątpliwości czemu nie są popularne membrany większe niż 18’’, nadmienię, że wynika z faktu, że jednocześnie chcemy by membrany były lekkie, o czym dokładniej może perzy innej okazji. Wskaże tylko to, że w większości pasma użytecznego prędkość membrany wynika z bezwładności masy, czyli ma charakter indukcyjny. Dlatego większa masa membrany w głośnikach promieniujących bezpośrednio to mniejsza sprawność.
Wracając do zagadnienia, znając zależność impedancji promieniowania od powierzchni, można dwa subwoofery (głośniki) z powodzeniem dla rozważań, zastąpić jednym zastępczym subwooferem (głośnikiem). Troszeczkę gimnastyki na bazie zwykłej mechaniki wymaga zrozumienie, że głośnik wypadkowy będzie miał dwa razy cięższą membranę (cały układ drgający), dwa razy mniejszą podatność zawieszeń, ale i wreszcie dwa razy większa powierzchnię membrany. To ostatnie wiąże się nie z dwa a cztery razy większą impedancją promieniowania. Stosując uproszczony układ zastępczy wskazany poprzednio, każdą z impedancji musimy pomnożyć przez dwa, w tym także źródło, jedynym wyjątkiem jest impedancja promieniowania. Przy niewielkiej impedancji promieniowania prędkość wypadkowej membrany pozostanie niemal bez zmian, ale poczwórna impedancja promieniowania zaowocuje dwukrotnie większą skutecznością.
Naturalną konsekwencją zrozumienia omawianego problemu staje się pytanie do jakiego momentu możemy podwajać suby, zachowując to prawo. Wszak na pierwszy rzut oka widać, że gdy impedancja promieniowania zbliży się do impedancji elektrycznej głośnika (przeniesionej na stronę mechaniczną), to zyski sprawności zaczynają być mniejsze. Warto nie tracić z oczu, że teoretyczna sprawność 100%, choć i tak nie osiągalna, z cała pewnością nie może być przekroczona. Do tej pory zamiennie używałem słowa skuteczność i efektywność. Przypomnę więc, że skuteczność jest miarą przetwarzania energii elektrycznej na energię dźwięku, a efektywność jest miarą przetwarzania energii elektrycznej w natężenie dźwięku. Natężenie jest w istocie gęstością powierzchniową przepływającej mocy, przeto dla źródeł wszechkierunkowych energia przepływa przez całą powierzchnię kuli. Dlatego też dla źródeł wszechkierunkowych obie wartości są połączone stałym współczynnikiem, który wynosi 4Pi i jest to po prostu powierzchnia kuli o promieniu 1m. Jako ciekawostkę, jednocześnie ku przestrodze w czytaniu fantastyki marketingowej, nadmienię, że skoro 0dB oznacza natężenie odniesienia 10^-12 W/m^2, to nietrudno policzyć, że dla kuli o powierzchni 4Pi (11db) 1W, czyli 120dB więcej niż poziom odniesienia, podzielony przez powierzchnię 4Pi (-11dB) da wynik 109dB. Oznacza to, że 100% energii wszechkierunkowej dla 1W odpowiada natężeniu 109dB (tyle samo ciśnienia akustycznego). Przy czym gdy impedancja promieniowania będzie równa impedancji elektrycznej, sprawność (uproszczona) będzie maksymalna i wynosiła 25% (103dB). W praktyce możliwe jest osiągnięcie sprawności rzędu 40% (105dB) w wąskim pasmie ze względu na to, że rezystancja cewki jest mniejsza niż impedancja znamionowa głośnika. Podsumowując należy między bajki włożyć subwoofery o sprawności większej.
Ale źródło nie zawsze jest wszechkierunkowe. Decyduje o tym dokładnie to, o czym mówiłem wcześniej, mianowicie rozmiar źródła w porównaniu do długości fali. A kiedy źródło zaczyna być kierunkowe, okazuje się że energia może przepływać przez mniejszą powierzchnię, osiągając w tej powierzchni większą gęstość mocy. To oznacza, że przy tej samej sprawności efektywność może być większa. Zależność efektywności od sprawności łączy parametr zwany zyskiem kierunkowości. Dla przeciętnych tub wysokotonowych zysk ten może wynieść koło 7-10dB, co w łatwy sposób doprowadza nas do teoretycznych wartości efektywności rzędu 109-114dB.
Wracając do postawionego pytania, z doświadczeń wynika, że prawo podwajania suba działa również nawet wtedy, gdy grupa osiąga dużą sprawność. Okazuje się, że jedna duża zastępcza membrana z powodu swych rozmiarów wchodzi w zakres promieniowania kierunkowego, gdzie zysk skuteczności zaczyna powstawać nie z zysku sprawności, a z zysku kierunkowości. Przy czym różnica jest tylko taka, że nie tyle zwiększyliśmy częstotliwość, co zwiększyliśmy rozmiar membrany. Dlatego też w praktyce przyjąć należy, że prawo podwajania efektywności działa również w przypadku grup o dość dużych rozmiarach, warto jedynie pamiętać o zawężaniu kierunkowości.
Na zakończenie pragnę zauważyć, że ten uproszczony sposób rozumowania od pojedynczego głośnika niskotonowego do zestawu głośników o bardzo dużej długości pomaga zrozumieć zasady rządzące akustyką od pojedynczego małego punktu promieniującego, do źródła wyrównanego liniowo. Przy okazji pomaga to zrozumieć również to, dlaczego w pobliżu źródła ciśnienie jest niezależne od odległości.
Draus Jarosław
09
cze 2015
Aktywna moda
W poszukiwaniu fenomenu dużej popularności aktywnych systemów nagłośnieniowych wśród przenośnych zestawów nagłośnieniowych średniego kalibru, przez kilka lat pytałem każdego potencjalnego klienta, czemu pyta mnie o aktywny zestaw nagłośnieniowy. Słyszałem poniższe odpowiedzi tak wiele razy, że postanowiłem zamiast czuć się jak w „dniu świstaka” odsyłać do przeczytania poniższego tekstu.
„Aktywny jest mniejszy.”
Czego oczy nie widzą… ale zejdźmy na ziemię: w aktywnych kolumnach wzmacniacze istnieją i są ze względów bezpieczeństwa zamknięte w swojej komorze pomniejszając obudowę w sensie akustycznym. Rozmiary wzmacniaczy są mniej więcej takie same w aktywnych i pasywnych. W aktywnych komora wzmacniacza jest wykonana zwykle z drewna, przy czym tych komór na wzmacniacze jest tyle ile kolumn. Prawidłowa logika jest taka, że bas aktywny i pasywny są odpowiednikami dopiero wtedy, gdy aktywny jest powiększony o pojemność komory ze wzmacniaczem. W zestawie 2+2 są 4ry wzmacniacze i zajmują zazwyczaj znacznie więcej miejsca niż jeden wzmacniacz we wspólnej obudowie stalowej. Oczywiście można pokazać np bas pasywny i aktywny o tym samym rozmiarze, ale bas aktywny będzie mniejszy (akustycznie), a mniejszy bas (przy zachowaniu innych parametrów) jest obiektywnie patrząc zawsze gorszy (odsyłam do artykułu o tubach). Co więcej, nie ulega wątpliwości, że cena 4rech zasilaczy będzie większa niż jednego o 4ro krotnie większej mocy. Warto jednak pamiętać, że do nagłaśniania ważnych imprez, warto mieć więcej niż jeden element systemu, więc nie mając dodatkowego wzmacniacza np do odsłuchu, warto przynajmniej rozważyć na wszelki wypadek przynajmniej dwa wzmacniacze dwukanałowe (zamiast 4rech niezależnych), co oczywiście nie zmienia faktu że dwa są nadal tańsze niż cztery. Reasumując, kolumna aktywna jest większa. Niepodważalnym prawem natury jest to, że bas jest większy niż satelita, więc wielkość basu jest parametrem decydującym w największym stopniu o osiągach całego mobilnego zestawu. Większe basy są skuteczniejsze (przy tym samym paśmie). Jest to o tyle ważne, że obecnie żaden mobilny zestaw nie potrafi odtwarzać pełnego pasma zawartego w materiale muzycznym, z odpowiednią skutecznością. Przy założonym kompromisie wielkości, skuteczności, dolnej częstotliwości można jedynie trochę uratować sytuację wybierając zestaw z głośnikiem o największej mocy. Ale szukając tego kompromisu coś innego jest ważniejsze, Warto zauważyć, że bas, do którego można na czas transportu cokolwiek schować (nadstawkę, wzmacniacze, kable) owocuje dalece większym zaoszczędzeniem miejsca, niż różnica, o której dywagowaliśmy na początku akapitu. Nowoczesny wzmacniacz w rozmiarze 1u op mocy rzędu 5kW zajmuje około 3 litrów. Przeciętna nadstawka zajmuje 30-60litrów, a bas który zaczyna cokolwiek sensownego odtwarzać przynajmniej 150litrów.
„Aktywny jest lżejszy.”
Niby jakim cudem? Jak już wiemy że wzmacniacze w aktywnych istnieją, to dlaczego kilka wzmacniaczy, np 4ry niezależne kanały, mają być lżejsze niż jeden wzmacniacz we wspólnej obudowie ze wspólnym zasilaniem? To oczywiście niemożliwe. Najbardziej istotna różnica w wadze jest taka, że w aktywnych zestawach basy, zawsze największe i najcięższe z całego zestawu są jeszcze bardziej ciężkie. W pasywnych część masy można przenieść do case’a z mikserem, lub do jeszcze odrębnej skrzyni, więc łączna waga jest zbliżona, ale maksymalna waga najcięższego urządzenia, czyli zazwyczaj basu (20-50kg), jest mniejsza. Większość basów mobilnych, walczy o o barierę 30kg. Dorzucenie do niego wzmacniacza rzędu 3-5kg, znacznie zmienia sytuację, ponieważ jest to ekwiwalent znacznie mocniejszego głośnika, np różnicy między 4 a 4,5 calowym napędem. Mając mocniejszy napęd można w ogóle zmienić koncepcję i wybrać jeszcze bas mniejszy o tych samych osiągach. Wynika z tego wprost, że zestaw aktywny jest mniej mobilny.
Jedynym wyjątkiem od tej reguły i dla pełnego obrazu trzeba o tym napisać, jest sytuacja, w której w ogóle nie ma miksera, tylko mikrofon podłączony bezpośrednio do tylko jednej małej aktywnej paczki szerokopasmowej. To jest jedno z niewielu rodzajów zastosowań, w których aktywny się sprawdza lepiej. Jednakże warto nie tracić z oczu celu takiego, że sprzęt musimy dobrać do potrzeb największych a nie najmniejszych.
Aktywny jest zazwyczaj lżejszy dlatego, bo posiada słabsze, tańsze, z mniejszym napędem głośniki, a więc dlatego, że jest gorszy. Kwintesencją zagadnienia z punktu widzenia marketingu i poziomu sprzedaży jest to, że wykrycie tego faktu, iż zestaw nic ciekawego sobą nie reprezentuje jest trudniejsze. Obecnie aktywne systemy nagłośnieniowe, sa opisywane w sposób, w jaki jeszcze kilka lat temu mógł się kojarzyć tylko z bazarem z chińskimi podróbkami, a nie z profesjonalnym sprzętem. Brak skuteczności, parametr SPLmax kompletnie oderwany od rzeczywistości, brak wykresu lub wykres po procesorowaniu, podawanie mocy wzmacniaczy peak na impedancjach, których nie ma w kolumnie itp, to jest ewidentny trick marketingowy, który ma na celu dobro pośrednika, a przez to dobro producenta, a nie dobro użytkownika. Powstaje w ten sposób pewnego rodzaju zachwianie równowagi popyt-sprzedaż, poprzez to, że kupujący nie wie dokładnie co kupuje, ma bardzo ograniczone możliwości oceny, a na tacy podaje mu się to, co dla znawcy wydaje się niemożliwe do osiągnięcia.
„Mniej kabli”
Zadziwiające jest jak wielu zainteresowanych powtarza tę bzdurę kompletnie nie zastanawiając się nad tym jaka jest rzeczywistość. Przecież w zestawie aktywnym do każdej kolumny trzeba dostarczyć nie tylko kabel sygnałowy, ale także zasilający. Podczas gdy w tej samej sytuacji w zestawie pasywnym wystarczy jedno zasilanie centralne i po jednym kablu głośnikowym. Różnica jest więc tylko i wyłącznie z kablach zasilających i możliwości (lub nie) centralnego zasilania. W typowym, dobrze skonfigurowanym pod względem mobilności zestawie potrzeba podłączyć:
Zestaw 2+2 / 2+1
Pasywny: 5kabli / 4 kable
Aktywny: 9kabli / 8 kabli
W pasywnym podłączamy jedno zasilanie do case’a z mikserem i wzmacniaczami, jeden kabel do każdej kolumny. W zestawie aktywnym dodatkowo zasilanie do każdej kolumny. Warte uwagi, że transportowanie miksera oddzielnie nie zmienia przewagi pod tym względem. Ponadto warte podkreślenia, że wszelkie sztuczki związane z łączeniem kabli w grupy, nie zmieniają tego, że w pasywnym zestawie stosując podobne tricki będzie zawsze mniej kabli.W zestawach do mocy rzędu 5kW RMS (około 10kW peak) cały system można przy naprawdę wrednym współczynniku szczytu, powiedzmy -3dB, zasilić bezpiecznie z jednego przedłużacza jednofazowego, bo jest to mniej więcej moc czajnika. Za to aktywne satelity, znajdujące się zazwyczaj szeroko, wymagają do zasilania nie tylko kabli tzw komputerowych, ale też przedłużaczy. Warto także zauważyć, że przedłużacze rzadko występują w pożądanym ze względów estetycznych, mniej widocznym kolorze czarnym.
„Bardziej praktyczny”
Skoro nie jest lżejszy, mniejszy, ani szybszy w montażu, to może coś innego?
Dość istotną cechą systemów nagłośnieniowych jest możliwość centralnego zarządzania, tj możliwości podjęcia decyzji i regulacji z dogodnego miejsca, najlepiej miejsca słuchacza. Sterując wszystkimi możliwymi parametrami począwszy od głośności, proporcji sub/sat, poprzez bardziej zaawansowane częstotliwość podziału, korektor, korektor dynamiczny, poziom limitera pasmowego, każdy znawca swojego sprzętu jest w stanie przynajmniej usłyszeć czy jakiekolwiek zmiany przynoszą skutek. W zestawie aktywnym, nawet dobranie prawidłowej proporcji bas/sat jest uciążliwe, ponieważ trzeba za każdym razem podejść do wszystkich subwooferów lub satelit, żeby chociażby skorygować głośność. Nie jest prawdą, że zestaw aktywny podłączony do prądu gra zawsze idealnie. Chociażby należy przywołać jedną z podstawowych praw elektroakustyki, że bas w pobliżu ściany/ podłogi gra nawet w dużym pomieszczeniu z każdą sąsiednią powierzchnią o 3dB głośniej. Łączna różnica pomiędzy narożnikiem a pełną przestrzenią wynosi z samego tylko otoczenia 9dB (niemal dziesięciokrotna różnica w mocy). A w małych pomieszczeniach dochodzi dodatkowo kumulacja głośności z powodu zjawiska pogłosu. Już tylko z tych powodów każde nowe miejsce wymaga regulacji.
„Bardziej niezawodny”
Pojedyncze urządzenie w torze zawsze jest najbardziej newralgiczne. W małych zestawach pojedyncze urządzenia będą istnieć, bo trudno sobie wyobrazić, żeby zespół, DJ inwestowali w podwójny mikser, czy procesor głośnikowy. Niemniej są to urządzenia mniej wrażliwe na trudne warunki (skoki napięcia/ wilgoć/ temperatura/ dym/ woda/ piasek) w porównaniu z kolumnami i wzmacniaczami. Na trudne warunki, w szczególności w plenerze bardziej narażone są zestawy aktywne. W pozostałych przypadkach:
Usterka kolumny nie rożni zestawu aktywnego czy pasywnego, w obu przypadkach należy się liczyć z brakiem jednego źródła. Z tą różnicą, że w pasywnym zestawie wzmacniacz pozostaje gotowy do użytku. To skraca i upraszcza problem, czasami do użytku można nawet przeznaczyć monitor.
Usterka wzmacniacza to co innego. W pełni niezależnym układzie aktywnym brak jest jednego źródła. W układzie pasywnym jest wybór: albo będzie brak źródła, albo można się przełączyć w tryb mono lub inny z mniejsza mocą używając wszystkich źródeł. Można również wykorzystać wzmacniacz rezerwowy lub odsłuchowy, a serwis uszkodzonego jest mniej problemowy.
Najbardziej niebezpieczne są zestawy z centralnym wspólnym wzmacniaczem (zarówno aktywne jak i pasywne). Warto mieć świadomość i nie stosować takich zestawów w szczególnie ważnych przedsięwzięciach. Szczególnie niebezpieczne jest wspólne zasilanie impulsowe, w kompaktowym zestawie aktywnym ponieważ usterka wyklucza w zasadzie cały system. I znów przewaga pasywnego jest taka, że zabierając wzmacniacz rezerwowy na szczególnie istotne imprezy zyskujemy pewność, że jedna usterka nie spowoduje końca imprezy.
Wnioski końcowe.
Często jestem pytany, czemu w takim razie ludzie ulegają takiej zbiorowej halucynacji. Mam świetny przykład. Powszechnie wiadomo, że państwo które daje obywatelowi 100zł w postaci przywileju, musi zabrać obywatelowi więcej, dajmy na to 150zł w postaci podatku, choćby po to, żeby zatrudnić urzędnika, który będzie się tym zajmował. Niestety ogromnej większości obywateli to nie przeszkadza ponieważ tego nie widzą i dlatego głosują na ludzi, którzy jeszcze bardziej im zwiększają podatki. Tak właśnie stało się z modą na aktywne zestawy nagłośnieniowe – sprzedają się wyśmienicie, nakręcają rynek, a klienci zapominają, że w środku też są wzmacniacze. Wielu, szczególnie początkujących odbiorców sprzętu, którym dedykuję niniejszy tekst, daje się nabrać zupełnie bezpodstawnie na nadzwyczajne dane techniczne. Fenomen jest więc w sumie prosty – wystarczy jak najbardziej zagmatwać klientowi dokumentację, a przeczyta ją tak jakby chciał ją przeczytać, a nie tak jak jest w rzeczywistości. Przy niewygórowanej cenie, ogromnej ilości marek wykrycie prawdy jest stosunkowo mało prawdopodobne. Polecam więc, niech przy zestawach aktywnych pozostaną Ci świadomi, którzy naprawdę mają na to ochotę, znają dokładnie swój sprzęt, a nie Ci, co kupują kota w worku, z powodów, które wymieniłem powyżej.
11
wrz 2014
STK610M
Ultralekka satelita
Najmocniejsza obecnie 10tka na rynku. Konstrukcja 10”+1,75”neo. Świetnie nadaje się do nagłośnień weselnych, w małym klubie, dla DJa mobilnego. Można też wykorzystać jako bardzo kompaktowy mocny monitor.
Brzmi bardzo podobnie do STK512, jest tylko nieznacznie mniej sprawna ale za to możliwe jest schowanie jej w transporcie do znacznie mniejszego subwoofera – HF12.
STK610 jest produktem przeznaczonym zwłaszcza dla tych odbiorców, dla których przeniesienie zestawu za pomocą wyłącznie jednej osoby jest kluczowe.
Konstrukcja 10” (RCF MB10N305 ) + 1,75” (RCF ND350) .
Pasmo: 90Hz-20kHz
Moc 600W RMS (szrokopasmowo).
Rozmiar (WxDxH): 340x300x530 mm
SPL=98dB @1W/1m
Waga: 12,5kg
Pasmo: 90Hz-20kHz
18
lut 2014
O technologiach stosowanych w głośnikach estradowych
Dziś kilka słów o najpopularniejszych technologiach stosowanych w nowoczesnych głośnikach estradowych, które robią różnicę i na które warto zwrócić uwagę. Dla zobrazowania istotności poniżej przedstawionych rozwiązań wskażę, że wszystkie pierwsze 7 technologii stosowane jest w prawie każdym głośniku uznawanym za profesjonalny.
1) Wymuszone chłodzenie. Ponieważ zapotrzebowanie na moc głośników niskotonowych stale jest niezaspokojone, a dalsze zwiększenie średnicy cewek stało się niemożliwe z powodu zbyt wielkiej masy drgającej, ograniczającej sprawność przetwarzania, już kilka dekad temu zaczęto wykorzystywać powietrze generowane przez głośnik do chłodzenia własnej cewki. Przez lata sposób chłodzenia ewoluował. Przez jakiś czas rozwiązaniem charakterystycznym było poprowadzenie jednego centralnego otworu w wewnętrznym nabiegunniku. Wymusza to ruch powietrza od komory pod zawieszeniem dolnym przez obie strony cewki a ruch powietrza w centralnym otworze powoduje wymianę powietrza z otoczeniem. Jednym z pierwszych głośników estradowych, które przekroczyły 1000W, były głośnik „Kilomax” firmy Eminence, w którym zastosowano dodatkowwe chłodzenie za pomocą otworów w nabiegunniku wewnętrznym, umieszczonych na okręgu przedłużającym cewkę. Na przełomie wieku powstały i stosowane są do dzisiaj, wbrew marketingowemu rozwojowi branży – bez istotniejszych innowacji, głośniki wentylowane trzema drogami. Otwory są zarówno z komory pod dolnym zawieszeniem, najczęściej poprzez mało widoczne otwory pomiędzy koszem a magnesem. Druga droga to otwór centralny w nabiegunniku wewnętrznym, a trzecia droga to otwory umieszczone w nabiegunniku wewnętrznym na obwodzie takim samym jak średnica cewki. Wszystkie te metody, poprzez zmniejszenie rezystancji termicznej pomiędzy cewką a nabiegunnikami, spowodowały znaczny wzrost mocy znamionowych, przy zachowaniu tej samej masy a więc tej samej sprawności głośnika.

2) Aluminiowy drut. Technologia stosowana jest przede wszystkim w głośnikach nisko-średniotonowych (midbas), średniotonowych i driverach wysokotonowych, stosowana praktycznie przez wszystkich producentów przy największych mocach. To właśnie w tych głośnikach masa układu drgającego jest kluczowa, a stosunkowo niska prędkość powietrza w szczelinie magnetycznej uniemożliwia równie skuteczne chłodzenie wymuszonym powietrzem, co w głośnikach niskotonowych. Ponadto małe lekkie membrany powodują, że udział masy cewki w całkowitej masie drgającej jest największy. Główną zaletą jest oczywiście niższa masa aluminium , przy niewiele mniejszej przewodności elektrycznej od miedzi.
3) ISV (interleaved sandwich coil). Technologia prostąkątnego drutu miała największa popularność na przełomie wieku. W dzisiejszych głośnikach nastąpiło wyraźne rozgraniczenie pasm. W najnowszych, najbardziej udanych głośnikach niskotonowych jak na razie zaprzestano stosować tę technologię na korzyść techniki nawijania obustronnego drutem o przekroju okrągłym. W głośnikach midbas stosuje się najczęściej również obustronnie nawijany drut, ale aluminiowy. W głośnikach wysoko tonowych (ze względu na bardzo cienki przekrój), stosuje się nadal drut płaski aluminiowy, nawijany po zewnętrznej stronie karkasu. Cewka dwustronnie nawijana jest jednym z istotniejszych pomysłów na zwiększenie wydzielania mocy w ciągu ostatnich 20 lat w zakresie głośników midbas, w których technologie wymuszonego ruchu powietrza nie mają tak dużego znaczenia jak w basach. W standardowych cewkach nawijanych jednostronnie, karkas, będący zawsze izolatorem stanowi przeszkodę w oddawaniu mocy do nabiegunnika wewnętrznego. Pewnym postępem było zastosowanie kaptonu jako materiału nieźle przewodzącego ciepło, jak na elektryczny izolator. Ale nie ma wątpliwości, że oddawanie ciepła poprzez każdą warstwę drutu bez pośrednictwa karkasu daje poprawę chłodzenia nie tylko w głośnikach niskotonowych, ale we wszystkich. Choć obecnie ze względu na trudności technologiczne nie są mi znane żadne przypadki, należy się spodziewać, że połączenie obu technologii, tj nawijania płaskim drutem cewek obustronnych będzie jednym z rozwiązań w przyszłości.

4) DSS (double silicone spider) Technologia spopularyzowana przez firmę 18sound już w poprzednim wieku. Polega ona na sklejaniu dwóch (lub więcej) resorów poprzez elastyczny odporny na wysoką temperaturę silikon. Efekt jest taki, że standardowe zawieszenie z tkaniny w spotkaniu z bardzo dużym wychyleniem rozciąga się trwale, podczas gdy zawieszenie z silikonem wielokrotnie lepiej zapamiętuje swój kształt. Ponadto moment zatrzymania membrany jest bardziej płynny, co owocuje mniejszym rozciąganiem zawieszenia, oraz przeniesieniem zniekształceń w nie tak wysokie częstotliwości. Ma to bezpośrednie przełożenie na mniejsze zmiany podatności (sprężystości) zawieszenia, ale także przeciwdziała przesuwaniu się położenia środkowego membrany (w spoczynku) pod wpływem starzenia się zawieszenia. Jako dowód skuteczności tego rozwiązania niech będzie fakt, że w ślad firmy 18sound prawdopodobnie z powodu wygaśnięcia patentu, kilka lat temu poszły inne włoskie firmy. Najpierw B&C, a później także RCF. Dziś rozwiązanie stosuje coraz więcej firm produkujących głośniki i jest ono znacznie bardziej popularne niż potrójne resory.
5) Pierścienie demodulacyjne (single or double demodulation rings -DDR ). Pierścienie, zwykle aluminiowe tworzące zamknięty zwój dla cewki która wychodzi poza nabiegunnik. Ich zastosowanie jest najważniejsze w głośnikach midbas, ze względu na zmniejszanie zniekształceń powodowanych przez zmianę indukcyjności cewki w zależności od położenia cewki względem szczeliny magnetycznej . Pierścienie są po prostu zamkniętymi zwojami z materiału niemagnetycznego, w przeciwieństwie do silnie magnetycznych nabiegunników. W głośnikach niskotonowych, oprócz lepszej kontroli membrany wychodzącej poza szczelinę, ich rolą jest także fizyczne przedłużanie nabiegunnika, zwykle wewnętrznego, co ma także pozytywny wpływ na oddawanie mocy przez cewkę przy dużych wychyleniach.
6) Prostokątny przekrój drutu. Prawidłowa interpretacja celu tego rozwiązania jest taka, że to umożliwia dodatkowo zmniejszenie rezystancji przypadającej na dane pole powierzchni przekroju. Mniejsza rezystancja to większy stosunek BL^2/Re. Patrząc z punktu widzenia stałej wartości Re jest to dokładnie ta sama zaleta co zwiększenie siły napędu BL. W przeciwieństwie do cewek dwu lub więcej warstwowych nawijanych drutem okrągłym, zaletą drutu o przekroju prostokątnym jest także zmiana impedancji znamionowej głośnika na dowolną, bez zmian w układzie magnetycznym. To rozwiązanie również jest istotne przede wszystkim w przypadku głośników innych niż niskotonowe. Trochę problemów przysparza w praktyce połączenie drutu aluminiowego z wyprowadzeniami i przeprowadzenie przez karkas drutu od dołu cewki do góry, co wynika z faktu, że cewki prostokątne są zazwyczaj jednowarstwowe. Zwykle rozwiązuje się to w ten sposób, że drut jest po prostu płaski, ma duży rozrzut długości boków, Grubość drutu jest rzędu grubości karkasu i doprowadzenie do dolnej części cewki umieszcza się w szczelinie karkasu.
7) Przerwana cewka (split wire). Rozwiązanie stosowane w największych głośnikach niskotonowych. Przy dużych wychyleniach, kiedy cewka wychodzi częściowo poza szczelinę, membrana z powodu zmniejszenia BL poza szczeliną ma tendencję do przesuwania składowej stałej z punktu położenia w spoczynku. Tak skonstruowana cewka z przerwą powoduje na wykresie BL względem położenia cewki zmniejszenie szczytu w pozycji środkowej cewki. To z kolei przeciwdziała przemieszczaniu się zera położenia membrany przy bardzo dużym wychyleniu.
8) Głębokie zawieszenia membrany. Wraz ze zwiększaniem mocy cieplnej pojawiała się potrzeba lepszego mechanicznego prowadzenia membrany przy dużych wychyleniach. Idea podwójnego dolnego zawieszenia lub inaczej potrójne zawieszenie całego głośnika bez silikonu było stosowane już w latach 90tych XX wieku. Jako przykład możemy podać firmę Beyma stosującą to rozwiązanie np w głośniku 18G50 (550). Rozwiązanie miało pomóc w zachowaniu lepszemu zachowaniu współosiowości cewki przy dużych wychyleniach i doprowadzić do lepszej symetrii podatności zawieszenia. Rozwiązanie to pomogło w tym, jednak w większości głośników nigdy nie było szczególnie istotne jak nieidealnie symetrycznie zachowuje się zawieszenie gdyż większy udział w zniekształceniach mają inne czynniki, a rozwiązanie zastosowane w tym głośniku miało wadę z powodu zbyt małej średnicy resora w stosunku do ogromnej średnicy cewki. Rozwiązanie z trzecim resorem lepiej (w tamtych czasach) sprawdzało się np w głośniku kilomax firmy Eminence, ponieważ resor znajdował się na wysokości kopułki, mniej więcej w połowie odległości między resorem dolnym a górnym. Dzięki temu membrana mogła być trochę lżejsza, nie tracąc sztywności. Dodatkowo przy dużych wychyleniach mniejszym odkształceniom ulega cewka pomimo odkształceniom membrany spowodowanymi owalizacją czy ogólnie nie idealną współosiowością górnego resora. Niemniej w większości głośników zjawisku owalizacji przeciwdziała skutecznie grubo klejona kopułka, a górny resor wykonany w technologii „triple roll” ulega słabym odkształceniom od idealnego koła. Dziś w nowoczesnych głośnikach rozwiązanie z trzecim resorem stosuje się rzadko, o wiele popularniejsze stało się zastosowanie DSS w połączenieniu z potrójnie głęboko zrolowanymi oboma resorami, ale dla potrójnego resora wciąż typowym zastosowaniem jest głośnik koaksjalny – w celu poprowadzenia wysokich tonów przez środek membrany – w głośnikach koaksjalnych z tubą wysokotonową.
9) Ciekawym pomysłem, choć obecnie rzadko skotowanym, było zastosowanie przez firmę Eminence radiatora chłodzącego nabiegunnik wewnętrzny w głośniku Kilomax. Rozwiązanie oczywiście zmniejsza temperaturę nabiegunnika wewnętrznego, ale nie jest to rozwiązanie równie skuteczne, co chociażby obecnie najczęściej stosowana dwustronnie nawinięta cewka. Problem polega na tym, że podstawowym problemem nie jest oddanie ciepła z głośnika do powietrza, a oddanie ciepła z cewki do nabiegunników, które są bardzo dobrze połączone termicznie z koszem. To właśnie tutaj: cewka – nabiegunnik występuje największa różnica temperatur. Maksymalna temperatura cewki wynosi około 230’C, podczas gdy temeparatura nabiegunników zwykle nie przekracza 60-70’C, jeszcze niższa jest temeperatura aluminiowego kosza, który oddaje ciepło z nabiegunników. Być może jeszcze ktoś zastosuje to rozwiązanie, ale era głośnika kilomax dawno minęła z powodu nie posiadania pozostałych istotnych technologii. Odnotujmy, że firma Eminence zastosowała także podobną technikę, z radiatorem schowanym pod kopułką, w głośniku Magnum.
10) Differnential Drive. Bardzo ciekawe rozwiązanie – podwójną cewkę na tym samym karkasie z podwójnym układem magnetycznym zastosowała jako pierwsza firma JBL. Szczegółowe wyjaśnienie można znaleźć na stronie producenta: https://www.jblpro.com/pub/technote/JBL_TN%201-33%20rev3.pdf . Przestrzegam jednak przed bezkrytycznym czytaniem tego materiału. Producent stara się w nim wykazać, że zamiana jednej cewki na dwie dwa razy cieńsze podwaja powierzchnię nabiegunnika, a zatem podwaja też powierzchnię odbierania mocy, co miałoby znaczny wpływ na zwiększenie mocy głośnika. Na pierwszy rzut oka wszystko w porównaniu się zgadza, jednak troszeczkę pomyśleć wystarczy, żeby dostrzec, że to tylko sprytnie marketingowo spreparowany dowód typu 2+2=5. Otóż nikt przecież nie broni zrobić tego samego w głośniku z pojedynczym układem magnetycznym bez podzielenia cewki! Co to za problem zrobić dwa razy dłuższa cewkę z dwa razy dłuższym nabiegunnikiem? Jeśli tylko założymy, że cewka wypełnia całą szczelinę, to powierzchnia szczeliny też wzrośnie dwukrotnie, długość szczeliny spadnie dwukrotnie (za sprawą dwukrotnie cieńszej cewki), co zaowocuje takim samym natężeniem pola, takim samym stosunkiem kluczowego parametru BL^2/Re. Troszkę gimnastyki może zająć udowodnienie, że po takiej zmianie nie ulega zmiana rezystancji cewki, ale dla uproszczenia na potrzeby tego artykułu podam, że rezystancja cewki w ogólnie nie zmienia parametrów głośnika, a dla nie zaprzątania sobie głowy tym problelem można także przyjąć, że cewka w wyjściowym głośniku była czterowarstwowa i została zmieniona na dwuwarstwową, lub że drut był prostokątny i nastąpił podział jednego z boków prostokąta. A zatem dlaczego się tego nie robi w standardowych głośnikach? Odpowiedź jest prosta – część szczeliny magnetycznej, oprócz cewki, zajmuje powietrze. Zrobienie dwukrotnie cieńszej (ale dłuższej) cewki nie spowoduje, że długość szczeliny magnetycznej spadnie dwukrotnie. Typowy przykład z nowoczesnego głośnika niskotonowego o mocy rzędu 1kW: cewka o grubości 1,1mm z karkasem, luz w szczelinie 2x 0,55mm. Zmniejszenie cewki o 0,55mm spowoduje, że przy tym samym technologicznym zapasie luzu w szczelinie długość szczeliny spadnie z 2,2mm do zaledwie 1,65mm a nie do 1,1mm jak to wcześniej było sugerowane w uproszczeniu. Dobór szczeliny w każdym głośniku to kompromis pomiędzy pozostałymi parametrami i warto założyć, że jest to kompromis już bliski optymalnego, a w takim przypadku podwojenie powierzchni nabiegunników spowoduje odejście od tej optymalności. Dlatego też nie jest prawdą, że rozwiązanie podane przez JBLa podwaja powierzchnię oddawania mocy. Nie widać tego również w praktyce, nie widać żadnej przewagi mocy tych głośników. Warto także zauważyć, że zachowanie tego samego luzu przy wydłużeniu cewki nie jest możliwe, ponieważ większym bocznym odkształceniom będzie poddawana cewka. Reasumując -to mit i od razu obalony.
Niemniej jednak rozwiązanie ma swoje zalety, o których warto wspomnieć. Podzielenie układu magnetycznego na pół, umożliwia zastosowanie bardzo zwartego układu magnetycznego w przypadku magnesu neodymowego umieszczonego najczęściej wewnątrz cewki, bez konieczności prowadzenia nabiegunnika dookoła, na druga stronę cewki. Oczywiście ze względu konieczności oddania ciepła do otoczenia głośnik nie zmniejszy się, jednak pozostałą cześć głośnika można zbudować nie ze stali magnetycznej, lecz z lekkiego odlewu aluminium. To pozwala na zmniejszenie całkowitej wagi głośnika. Druga choć mniej istotną zaletą jest powstanie symetrii indukcyjności z powodu odwrócenia bieguna drugiej części układu magnetycznego, co daje efekt podobny do stosowania pierścieni demodulacyjnych. Trzecią, stosunkowo mało istotną zaletą, jest możliwość zastosowania zwartego zwoju „stop coil”, który hamuje cewkę w momencie znacznego wykroczenia poza szczelinę, co zmniejsza obciążenie tym zadaniem resorów. Wadą rozwiązania jest zwiększenie głębokości głośnika, przy zachowaniu tego samego zapasu przeciwdziałającego uderzeniu cewki o nabiegunnik.
Podobne rozwiązanie o nazwie „tetracoil” zastosowała firma 18sound w głośniku 18TLW3000. Celem tego rozwiązania nie było zastosowanie zwartego układu magnetycznego,gdyż zastosowano ceramiczny magnes, a tylko zwiększenie mocy przy zachowaniu 4” cewki. W mojej ocenie nie było to jednak udane posunięcie, gdyż głośnik nie posiada nadzwyczajnych parametrów i nie cieszy się powodzeniem. Zwiększenie mocy zostało okupione znacznym wzrostem masy drgającej. To, że konwencjonalne rozwiązanie spisuje się lepiej potwierdził to późniejszy głośnik z 5,3” cewką tej samej firmy.
11). AIC (active impedance control). Głośniki dwucewkowe są powszechnie znane, ale samo zastosowanie dwóch lub więcej cewek w celu dopasowania impedancji nie ma istotnego wpływu na jakość , czy osiągi głośników. Większe znaczenie ma zastosowanie dwóch różnych cewek. W bardzo starych głośnikach, w czasach kiedy głośniki były bardzo drogie, rozwiązanie z dwoma cewkami było stosowane w celu poszerzenia pasma. Jednak tutaj nie o tym mowa. Rozwianie zastosowane przez firmę 18sound w postaci dodatkowej nieruchomej cewki to coś niespotykanego dotąd. Cewka umieszczona w szczelinie magnetycznej linearyzuje impedancję, a pośrednio także zakres odtwarzania górnej części pasma. Wykres impedancji głośnika 10nd610 jest dowodem na to jak bardzo ograniczona zastała indukcyjność impedancji głośnika. Żaden głośnik na rynku o zbliżonej średnicy nie ma tak niskiej impedancji przy wysokich częstotliwościach, co wynika z drastycznego zmniejszenia składowej indukcyjnej impedancji.
04
gru 2013
Najnowsze komentarze